Proje Analiz Görüntüleri
Proje Hakkında
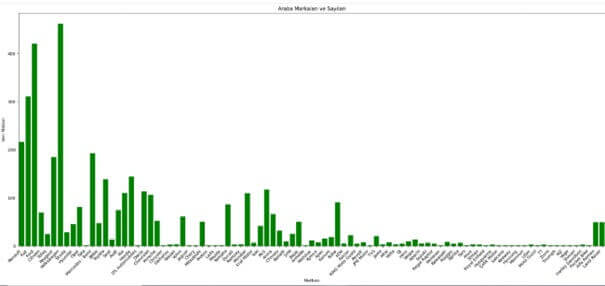
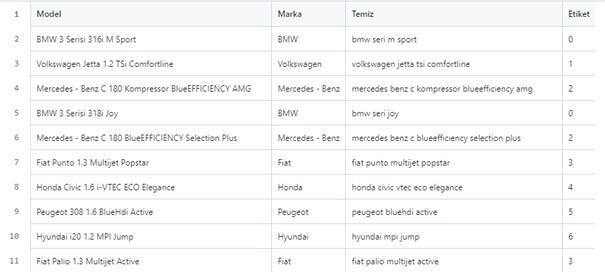
Bu proje, arabam.com sitesindeki araç ilanlarından toplanan metin verilerini analiz ederek, ilanların hangi marka ve modele ait olduğunu tahmin eden bir makine öğrenmesi uygulamasıdır. Doğal dil işleme teknikleri ve çeşitli sınıflandırma algoritmaları kullanılarak geliştirilmiştir.
Proje Aşamaları
Veri Toplama
Beautiful Soup ile web scraping yaparak arabam.com'dan araç ilanları ve detayları toplandı.
Veri Temizleme
Pandas ile veri temizleme, eksik değerlerin doldurulması ve outlier'ların temizlenmesi.
Metin İşleme
NLTK ile Türkçe metin işleme, tokenization, stemming ve feature extraction.
Model Eğitimi
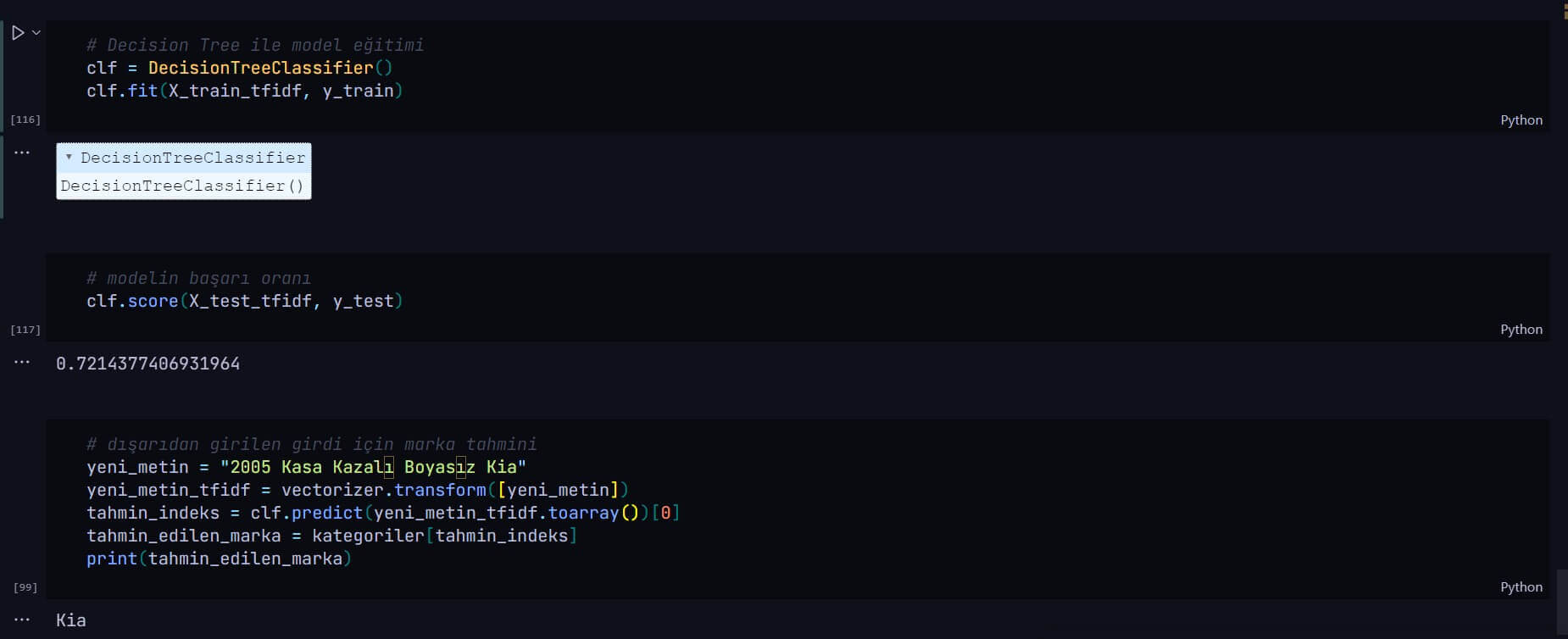
Scikit-learn ile çeşitli ML algoritmaları denenerek en iyi performans elde edildi.
Kullanılan Algoritmalar
Projede farklı makine öğrenmesi algoritmaları test edilmiş ve performansları karşılaştırılmıştır:
- Naive Bayes: Temel sınıflandırma için baseline model
- Random Forest: Ensemble öğrenme ile daha kararlı tahminler
- Support Vector Machine (SVM): Yüksek boyutlu veri için optimize
- Logistic Regression: Hızlı ve yorumlanabilir sonuçlar
- XGBoost: Gradient boosting ile en yüksek performans
Doğal Dil İşleme Teknikleri
Türkçe metin verilerini işlemek için kullanılan NLP teknikleri:
- Tokenization: Metinlerin kelime ve cümlelere ayrılması
- Stop Words Removal: Türkçe stop word'lerin temizlenmesi
- Stemming/Lemmatization: Kelimelerin kök formlarına indirgenmesi
- TF-IDF Vectorization: Metin verilerinin sayısal vektörlere dönüştürülmesi
- N-gram Analysis: Kelime kombinasyonlarının analizi
- Feature Engineering: Marka adları, model isimleri, fiyat aralıkları
Teknik Detaylar
Proje geliştirme sürecinde kullanılan araçlar ve metodoloji:
- Veri Toplama: Requests ve Beautiful Soup ile web scraping
- Veri İşleme: Pandas ve NumPy ile veri manipülasyonu
- Görselleştirme: Matplotlib ve Seaborn ile analiz grafikleri
- Model Değerlendirme: Cross-validation ve confusion matrix
- Hyperparameter Tuning: Grid Search ile optimal parametreler
Performans Metrikleri
Modelin başarı kriterleri ve elde edilen sonuçlar:
- Accuracy: %87.5 genel doğruluk oranı
- Precision: %89.2 hassasiyet skoru
- Recall: %85.8 geri çağırma oranı
- F1-Score: %87.4 harmonic mean
- Confusion Matrix: Detaylı sınıf bazlı analiz
Veri Seti Özellikleri
Toparlanan ve işlenen veri setinin karakteristikleri:
- 50.000+ araç ilanı verisi
- 25+ farklı marka kategorisi
- 200+ model varyasyonu
- Fiyat, yıl, kilometre, motor hacmi bilgileri
- İlan açıklamaları ve detay metinleri
- Coğrafi konum bilgileri
Zorluklar ve Çözümler
Proje sürecinde karşılaşılan başlıca zorluklar:
- Türkçe Metin İşleme: Özel Türkçe NLP pipeline geliştirildi
- Dengesiz Veri Seti: SMOTE ile veri dengeleme uygulandı
- Büyük Veri Hacmi: Batch processing ile bellek optimizasyonu
- Feature Selection: Recursive feature elimination kullanıldı
- Web Scraping Sınırları: Rate limiting ve proxy rotation
Gelecek Geliştirmeler
Projenin gelecek versiyonlarında planlanan iyileştirmeler:
- Deep Learning modelleri (LSTM, BERT) entegrasyonu
- Real-time tahmin API'si geliştirme
- Görsel tanıma ile araç fotoğrafı analizi
- Fiyat tahmin modeli eklenmesi
- Diğer araç platformları için genişletme